

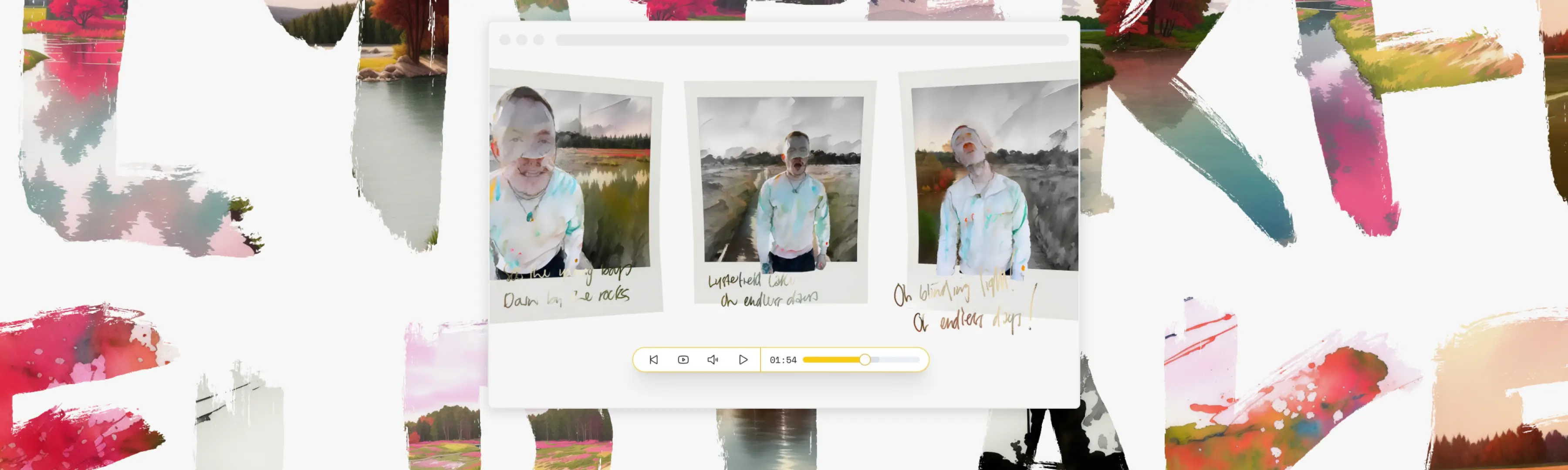

Lysterfield Lake is a song about a place outside Melbourne, Australia. It's about the endless summers of your youth, and the tiny changes in you that you don't even notice adding up. It's also about memories, which, like polaroids, fade and change over time.
I don't remember exactly when I wrote it in much the same way I don't remember exactly when I started this project, which has spanned the better part of a year and has all but consumed the most creative bits of my brain.
I think it all began when I came across Replicate (and by extention, their open-source container for running machine learning models, Cog.) I was so inspired by their Explore page, and, if I'm being totally honest, I was worried about the cost of experimenting with AI. I'd set up a gaming PC in the weird limbo of the 2020 lockdowns, and these tools made it effortless (and for the most part, free) to try, and test, and many, many times, fail.

Zoomable image
When I decided to release new music (it's been seven years since the last Brightly record) I knew I wanted to build something with these bits and pieces I'd been noodling with. I knew I wasn't great at making traditional music videos, and I felt empowered by the flexibility of the browsers, and the creative opportunties afforded by using machine learning and AI. I think the result is something greater than the sum of its parts.
And there are a lot of parts.
(Also, if you haven't seen the video, you should go and check it out before I ruin the magic by shining a very bright light on exactly how it all works.)
(And if you'd rather check out a recording, you can jump over to YouTube to see a simplified version that should give you a pretty good idea.)

What is it?
Lysterfield Lake is a 3D generative interactive music video. It works in the browser, using Three.js and react-three-fiber to stitch together seven feeds of video frame by frame, turning a single piece of footage shot on an iPhone into a three-dimensional fever dream. It uses the accelerometer in your phone, if it's available, or your mouse if you're on a computer. It shows and hides the protagonist as you watch depending on your actions, offering a myriad of ways to experience it. New dreams can be added at any time.
Behind the scenes it was modelled in Blender, (using a polaroid model by Edoardo Galati), generated in python and shell scripts, and built in JavaScript. It is made up of entirely open-source projects that are freely available.

The process
So, how does it work? I made a diagram to help.
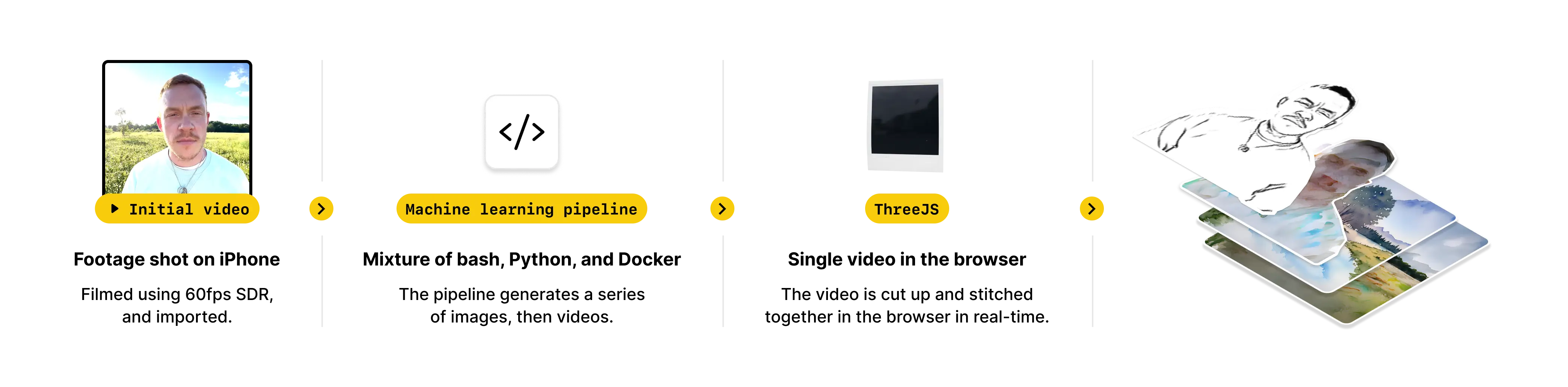
First, a single video file, shot on an iPhone, is fed through a series of python and shell scripts. The initial one splits the video into individual frames. These frames then go through a bunch of processes depending on their final output.

The original footage vs the final output. Note to self: I probably should've gotten a haircut before this.
The Avatar
A 3D-watercolour version of the subject matter (which is, in this case, me).
Zoomable image
- DiffusionCLIP turns the image into a painted watercolour style.
- RobustVideoMatting finds the subject in the video and creates an alpha mask of it.
- In python, the mask is used with the original image and passed to ZoeDepth, which creates a depth mask.
- These three elements (the watercolour image, the alpha mask, and the depth mask) are used to render the avatar.
The Background
A watercolour version of the original image, without the subject matter.

Zoomable image
- Using the alpha mask and the original image, Inpaint Anything creates a version of the scene without the avatar in it.
- This inpainted image is then also painted in watercolour using DiffusionCLIP.
- This element is then used to render the background.

The Outline
A comic-book style sketch of the subject matter.

Zoomable image
- In python, the original image is combined with the alpha mask to create a version with no background.
- This is then fed into artline-torch, which creates a rough outline sketch.
- This sketch is then overlaid on the avatar during rendering (it also uses a bit of dithering in the custom shader in Three.js, which is what gives it the printed ink / slight comic book style).

The Dreams
Prompt-generated reinterpretations of the original image.

Zoomable image
The original images are fed into Deforum Stable Diffusion, along with a prompt, creating unique scenes that mirror the subject matter. For example, trees and a lake that match the contours of the image.

Each frame is then manually reviewed one by one and removed if not appropriate. (The primary reason for this is that Stable Diffusion models are trained on image sets that include a large amount of waifus. Which, because the input clearly contains the shape of a person, means a lot of waifus end up in the output, even when politely asking Stable Diffusion not to.)

The remaining images are fed into rife-ncnn-vulkan, which interpolates the missing frames and generates new ones to fill the gaps.

The Lyrics

At the same time, I recorded myself handwriting the lyrics in Procreate, and then cleaned them up in Adobe's After Effects.
(Apologies for my handwriting. I clearly should've been a doctor.)
The Output

This gets stitched together into an ultra-wide video with 7 square images side-by-side. Originally I tried using a single video for each element, but it's impossible to guarantee frame sync across multiple videos in the browser. Fortunately, much like how there's no rule against eating a candy bar on a dance floor, there's no rule that videos need to be 16x9. Using custom shaders in the browser, you can simply grab the crop of footage you need for each element in real time.
And having all of these elements in the one shader affords new opportunities. By passing the depth mask, alpha mask, and the watercolour scene, I was able to generate a rough 3D model.

Custom shaders essentially let you paint with pixels in real time, and it's an incredibly exciting medium once you start to explore the possibilities. It is how I can use the pixels from the depth mask to directly impact how close or far each fragment of the 3D avatar is. And, if you'd like to learn more, The Book of Shaders is a great resource.

Each frame of each video includes the handwritten lyrics, the watercolour scene, the watercolour scene with the background removed, the alpha mask, the depth mask, the sketch, and the dream. And those ultra-wide videos form the backbone of the project.
The Conclusion
The selected dream, represented by one of these videos, is then chopped up and stitched back together in real time in the browser, using react-three-fiber, and many of the incredible resources provided as part of the drei project. You can explore each dream one by one, wandering through a landscape that has been imagined by a computer, listening to a song about a time that sits on the very edge of my consciousness. Memory, like AI, is funny like that.

This is probably a good time to mention that, while this is the conclusion, this project took every possible detour, hit every possible technical hitch, and explored every possible weird twist and turn. What I've ended up with is absolutely nothing like what I imagined, because I didn't really know what I was going to get at the end. Which makes it a sort-of love letter to the creative process, and to the joys of pursuing something purely for the “what-if” of it. There are so many ways that sticking with something can truly surprise you, and that doesn't have to involve making weird music videos — it could be baking, or cross stitch, or learning a language, or dance. Things you can experiment with, be creative with, grow with. Things that make you feel like you did something you previously couldn't. Maybe even something great. That might be the greatest feeling there is.
I hope you find it inspiring, or at the very least, mildly interesting, and I appreciate you taking the time to learn more about how the project works.
Okay, how do I find out more?

If you'd like to check it out, you can do so here:
https://lysterfieldlake.com/
If you'd like to share this project, that would be greatly appreciated. The project itself is entirely open-source, and available at the following GitHub repositories:
👉 Client App
A React app, powered by React and react-three-fiber.
👉 Pipeline
The pipeline that generates the video used by the app, powered by python and shell-scripts.
(Author's note: Fair warning—it's not the cleanest code, and in the case of the pipeline, it's not something that will work locally out of the box. I definitely intended open-sourcing this to be educational, in the sense of “oh, that's how he did that!”, as opposed to aspirational, like “oh, that's how he thinks React should be written??” Plausable deniability and all that. Cheers. 😅)